One way to get started with serverless computing is by building simple compute functions on cloud platforms such as AWS or Google Cloud. In this article, I am going to show you how to create a Lambda function that gets an object from a S3 bucket, does something with it and saves the output into the same bucket.
TABLE OF CONTENTS
OVERVIEW
Here’s an overview of the function we are going to create.

The Lambda function that we will be creating is a basic function that is first triggered by a PUT action (when someone creates or uploads a file) from the S3 bucket, to collect an object (or file) from the bucket. The function will parse the object and extract its contents to be processed by another service called Comprehend. Comprehend is a Natural Language Processing or NLP service provided by Amazon that is capable of various tasks such as sentiment analysis and key phrases extraction.
The data that we want to process is an array of texts and we want Comprehend to extract the key phrases from them to be used as tags for a website’s content. Once the extraction is complete, the results will be sent back to our function where they will be encoded into a file and stored into the bucket.
Disclaimer: It is usually recommended to store input and output files in separate buckets to prevent recursive invocations, but for simplicity we will use the same bucket with separate folders instead.
Let’s get started.
BUCKET CONFIGURATION
First of all, we need to create a S3 bucket to store our files. From the AWS Management Console, navigate to the S3 service and create a bucket (specify a region and leave everything as default).


CREATE FOLDERS AND UPLOAD OBJECT
Once we have our bucket, create a ‘data’ folder to store our initial data and a ‘output’ folder to store the response from our Lambda function. It is important to separate these two because if we look at the overview diagram, the Lambda function is triggered by a PUT action, so storing the output in the same directory will reinvoke the function.
Then, inside the ‘data’ folder, we will upload a JSON file called ‘texts.json’ containing an array of texts.


Now that we are done configuring our bucket, we can move on to Lambda in the next section.
FUNCTION CONFIGURATION
Head over to the Lambda service and click create a function.


At function creation, there will be options or templates we can choose from but in this example we will be building a Lambda function from scratch. Select ‘Author from scratch’, create a name for the function, and select Node.js as the language. Leave everything as it is and click ‘Create function’ at the bottom of the page.

Upon creation, we will be redirected to the function’s page. In the following sections, we will create a trigger for our Lambda function and start writing some code.
ADDING FUNCTION TRIGGER
At the top of the function’s page, go to the ‘Designer’ section and click ‘Add trigger’. This will bring us to an ‘Add trigger’ page.

Type S3 into the search field and select S3 to configure a trigger. This will prompt a new section underneath with multiple fields that we need to fill.
- Bucket : select the bucket we created earlier.
- Event type: under ‘all object create events’, select the ‘PUT’ option.
- Prefix : type ‘data’ to specify the directory with the uploaded object.
- Suffix (optional) : type ‘json’ to specify the object type of our file.
Note: If you have noticed, prefix and suffix are actually optional but since we are using the same bucket to store our input and output data, we MUST specify the prefix at least, to ensure that our Lambda function will only be triggered by a ‘PUT’ action within the ‘data’ directory.
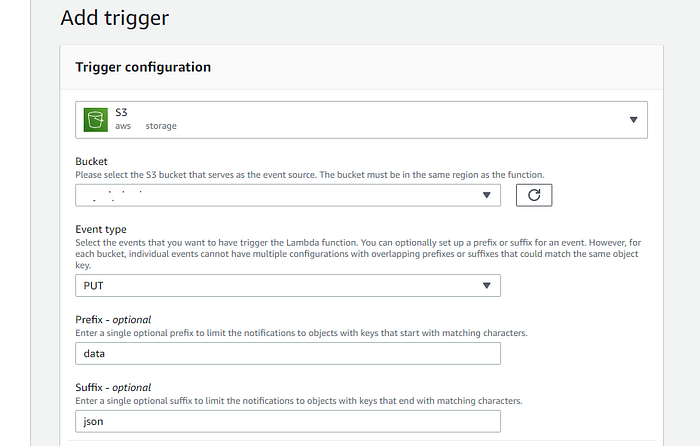
Once you have completed the form, scroll down and you will notice a warning about recursive invocations (this will not be an issue since we have already specified a directory), tick that you acknowledge the warning. Finally, at the bottom right, click ‘Add’.
If everything is okay, we should be redirected to the function’s page.
CODE FOR LAMBDA FUNCTION
At the function’s page, we will find an editor after the ‘Designer’ section. We will write our code here.
The function is very simple, we need AWS’s SDK for Javascript and 2 of its classes, S3 and Comprehend (you can access the documentation via this link). The function can be broken down into 3 steps:
- Get object from S3 bucket.
- Send object’s data to Comprehend and receive a response.
- Save the response as a new object and store it in the S3 bucket.
Firstly, we need to require ‘aws-sdk’ and create instances of the class we want to use.
const aws = require('aws-sdk);
const S3 = new AWS.S3();
const Comprehend = new AWS.Comprehend();Next, we will specify 2 objects called params1 and params2, params1 specifies the parameters required to get an object from a bucket whereas params2 specifies the parameters required to store an object in the bucket. To get on object, the required parameters are Bucket and Key; to store an object, the required parameters are Body, Bucket and Key. These parameters are defined as such:
- Bucket: name of the bucket (e.g. ‘my-bucket-123’).
- Key: object path inclusive of object name (e.g. ‘data/texts.json’).
- Body: object to be stored (e.g. a JSON encoded array).
const params1 = {
Bucket: '<bucket-name>',
Key: 'data/texts.json'
}const params2 = {
Bucket: '<bucket-name>',
Key: 'output/results.json',
Body: <object-content>
}
Then, we will create a function for each step of the flow: getObj (get object), prcObj (process object), and putObj (put object).
getObj() will call the getObject method of the S3 instance class to get an object based on the given parameters params1. Then, it will parse the object to return an array (we want the array of texts).
function getObj() {
return S3.getObject(params1).promise()
.then(data => {
let parsedData = JSON.parse(data.Body.toString());
return parsedData;
})
.catch(err => {
return err;
});
}prcObj() will call the detectKeyPhrases method of the Comprehend instance class based on 2 parameters, a string or text and the language code which specifies the language of the text. The response will be an array of objects, each containing various attributes such as confidence score and text. For this example, we just need the text of the response so we will create an empty array ‘res’ to store the texts from each of these objects.
function prcObj(text) {
let res = [];
return Comprehend.detectKeyPhrases({
LanguageCode: 'en',
Text: text
}).promise()
.then(async data => {
for(let i = 0; i < data.KeyPhrases.length; i++) {
let phrase = await data.KeyPhrases[i].Text;
res.push(phrase);
}
return res;
})
.catch(err => {
return err;
});
}putObj() will call the putObject method of the S3 instance class based on the given parameters params2. For this method, a response is not necessary but we will create a response message to log a report in CloudWatch. CloudWatch is a monitoring service which will log whatever is being done by our Lambda function. We will learn how to access these logs later in this article.
function putObject(body) {
return S3.putObject(params2).promise()
.then(() => {
let msg = 'success! check the 'output' directory.';
return msg;
})
.catch(err => {
return err;
});
}Finally, we will create a main function that will piece these sub-functions together and make the Lambda function complete.
The main function executes getObj() first to get the array of texts. Then, for each of these texts, prcObj() is called to turn them into individual arrays of phrases (or strings). At the last step, these arrays are pushed into a single array and “stringified” into JSON format before being stored to the target bucket by putObj().
exports.handler = event => {
return getObj()
.then(async data => {
console.log('texts: ', data);
let results = [];
for(let i = 0; i < data.length; i++) {
let phrases = await prcObj(data[i].text);
results.push(phrases);
}
console.log('results: ', results);
let msg = await putObj(JSON.stringify(results));
return msg;
.catch(err => {
return err;
});
}And that is it. Simple right? Basic function aside, AWS’s SDK and its comprehensive documentation makes it really comfortable for users to learn how to use their services.
FUNCTION DESTINATION (OPTIONAL)
Optionally, we can create a destination for our Lambda function to send notifications to other services based on success or failure of execution.
Go to the right portion of the ‘Designer’ section of our function’s page and click ‘Add destination’. This will lead us to a destination addition page where we can configure the function to notify services such as SNS or Simple Notification Service upon failed or successful executions.
After configuring the destination, scroll down and click ‘Add’ at the bottom right corner to finish adding the destination. The function will now notify a service we chose depending on the conditions we have specified.
TEST AND LOGS
Finally, we can test our Lambda function. Navigate to the target bucket and reupload the file.
Now how do we know if the function executed or not? And if it did, how can we check if it ran like it is supposed to?
Well there are a few ways to do this, or a few steps with no particular order.
- Check the output folder to see if a new object is created (obviously).
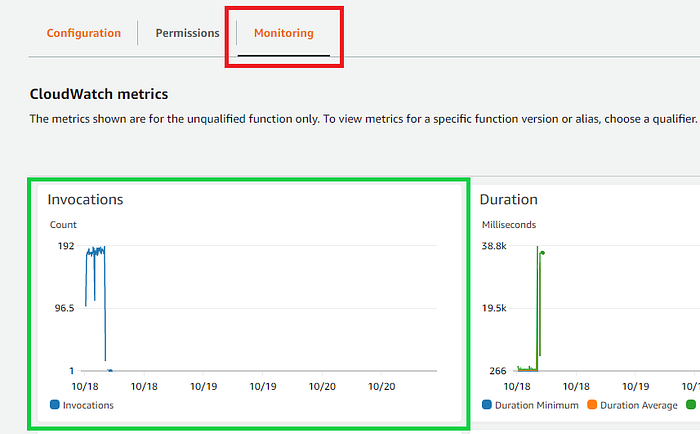
- Check the ‘Monitoring’ section of the Lambda function to see if there is any activity.
- Check the stream of logs recorded by CloudWatch.
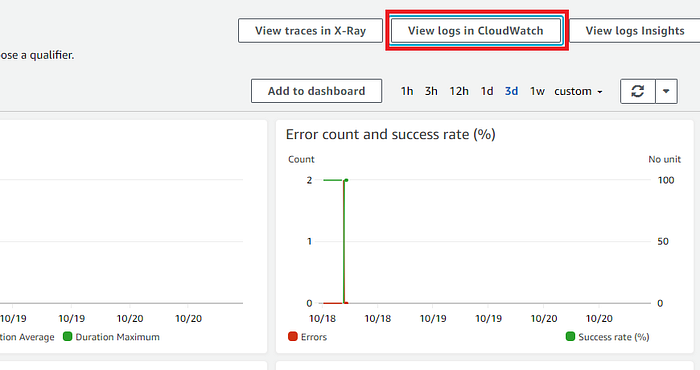
To the top right of the ‘Monitoring’ tab, click ‘View logs in CloudWatch’. This will lead us to a page showing all the logs that were recorded during each Lambda function execution (I will not attach a screenshot as it contains some confidential information).
The End :D
